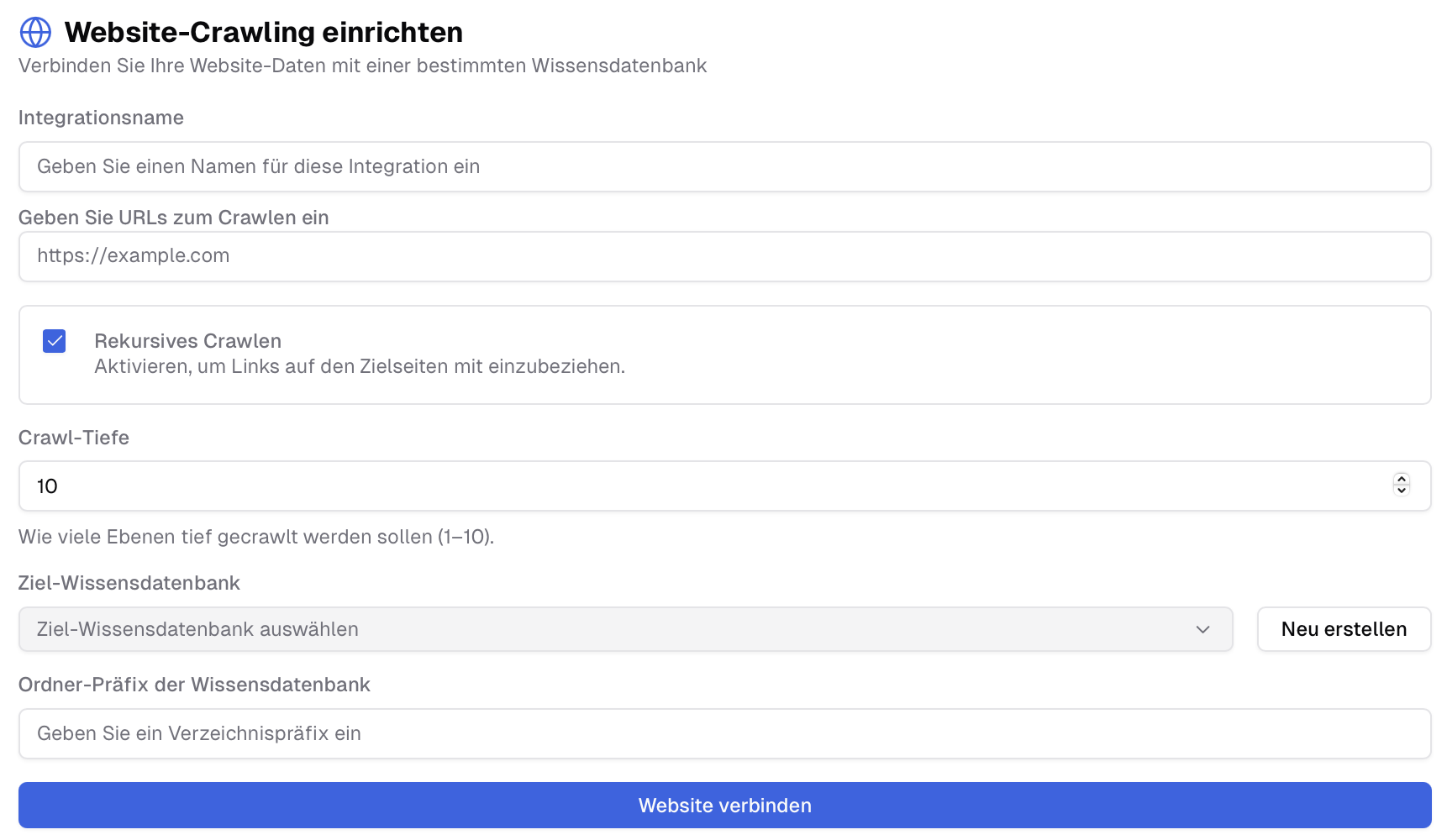
- Integrationsname: Wähle einen Name für diese Integration.
- URL: Die Webadresse, die vom System systematisch durchsucht und indiziert werden soll, um die Inhalte in die Wissensdatenbank der AI Suite zu integrieren.
- Rekursives Crawlen: Links, die der Cralwer auf der Website findet, werden ebenfalls besucht und gecrawlt. Rekursiv bedeutet, dass der Prozess fortlaufend weitergeht.
- Crawl-Tiefe: Bestimmt, wie tief die rekursive Suche durchgeführt wird (10 = 10 Links).
- Ziel-Wissensdatenbank: Die Wissensdatenbank, in der die gecrawlten Informationen gespeichert und verwaltet werden. Hier kannst Du entweder eine bereits bestehende Wissensdatenbank wählen oder eine neue erstellen.
- Ordner-Präfix: Name des Ordners in der Wissensdatenbank, in dem die gecrawlten Inhalte gespeichert werden.